Understanding Inference
Inference is the process of making predictions or generating outputs using a trained machine learning model. In production environments, inference refers to deploying the model and using it to make decisions in real-time or batch processing.
Why is Inference Important?
Efficiency: It enables the use of trained models for real-time applications like object detection, natural language processing, and more.
Scalability: Inference allows models to be deployed across various platforms and devices, ensuring they work efficiently at scale.
Optimization: Optimizing models during inference can reduce latency and resource consumption, making them suitable for deployment on edge devices.
In Matrice.ai, the Inference tab provides a streamlined process to export, optimize, and evaluate models for production-ready deployment.
Step-by-Step Guide to export the model using Matrice.ai
This section will guide you through the steps to export and optimize your models on Matrice.ai.
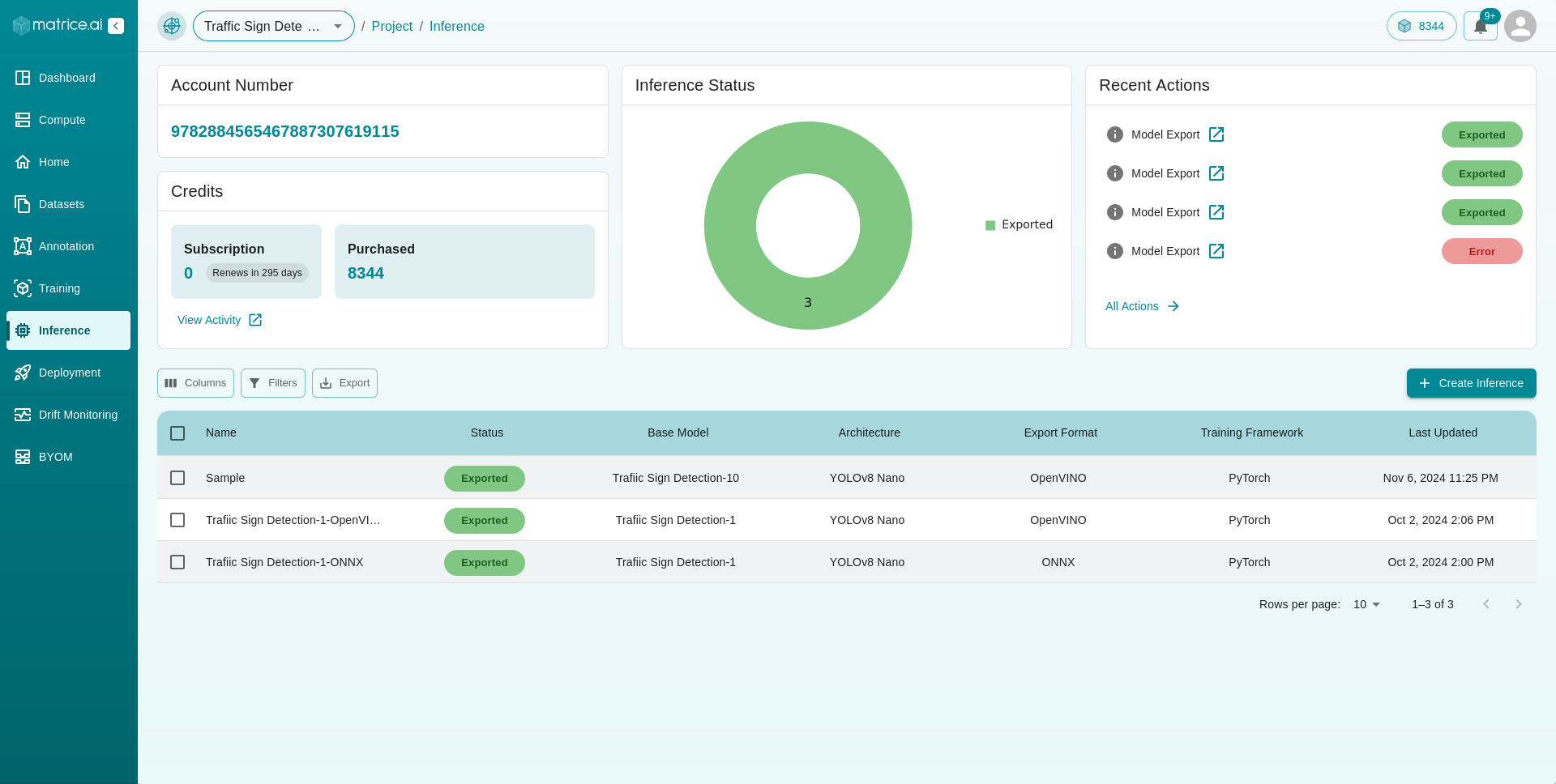
Navigate to the Inference Tab from the dashboard :
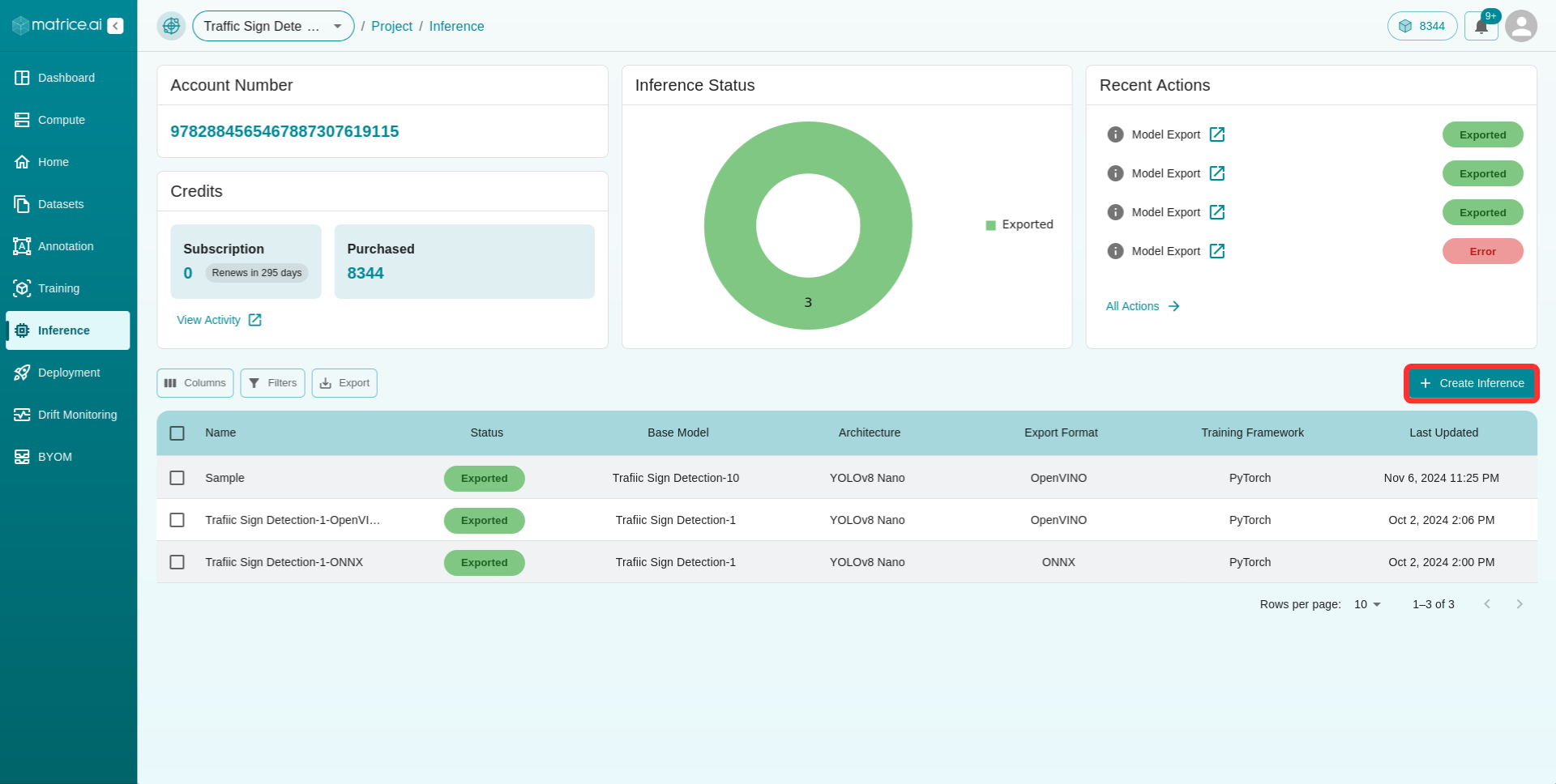
Select the Create Inference button to open the inference form :
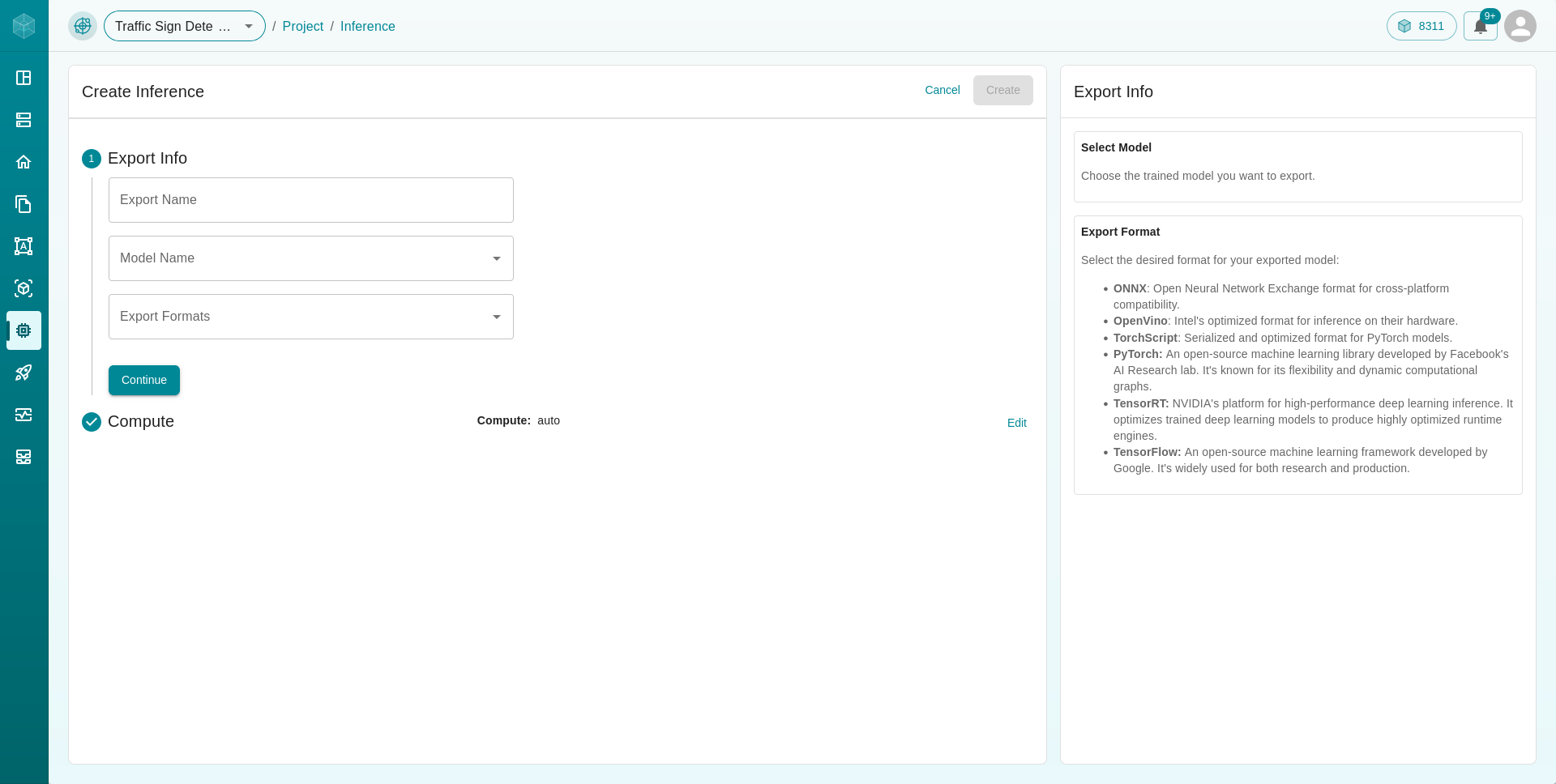
Enter the required information to add models for inference :
Choose a existing trained model to export from the dropdown menu.
Select the desired export format (e.g., ONNX, OpenVINO) and adjust hyperparameters as needed.
Choose the required hyperparameters for your model export.
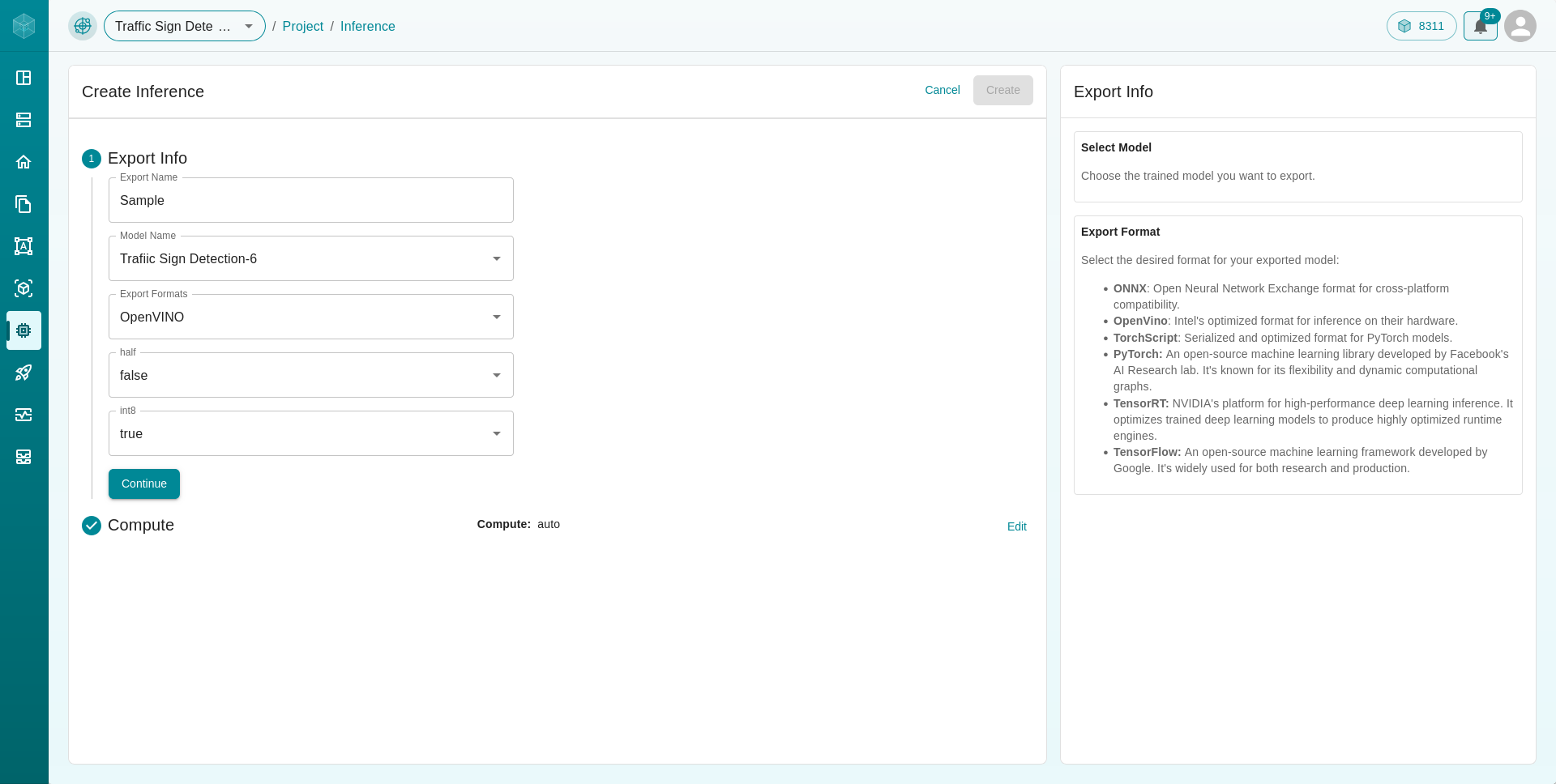
Export the Model by launching a new or dedicated instance
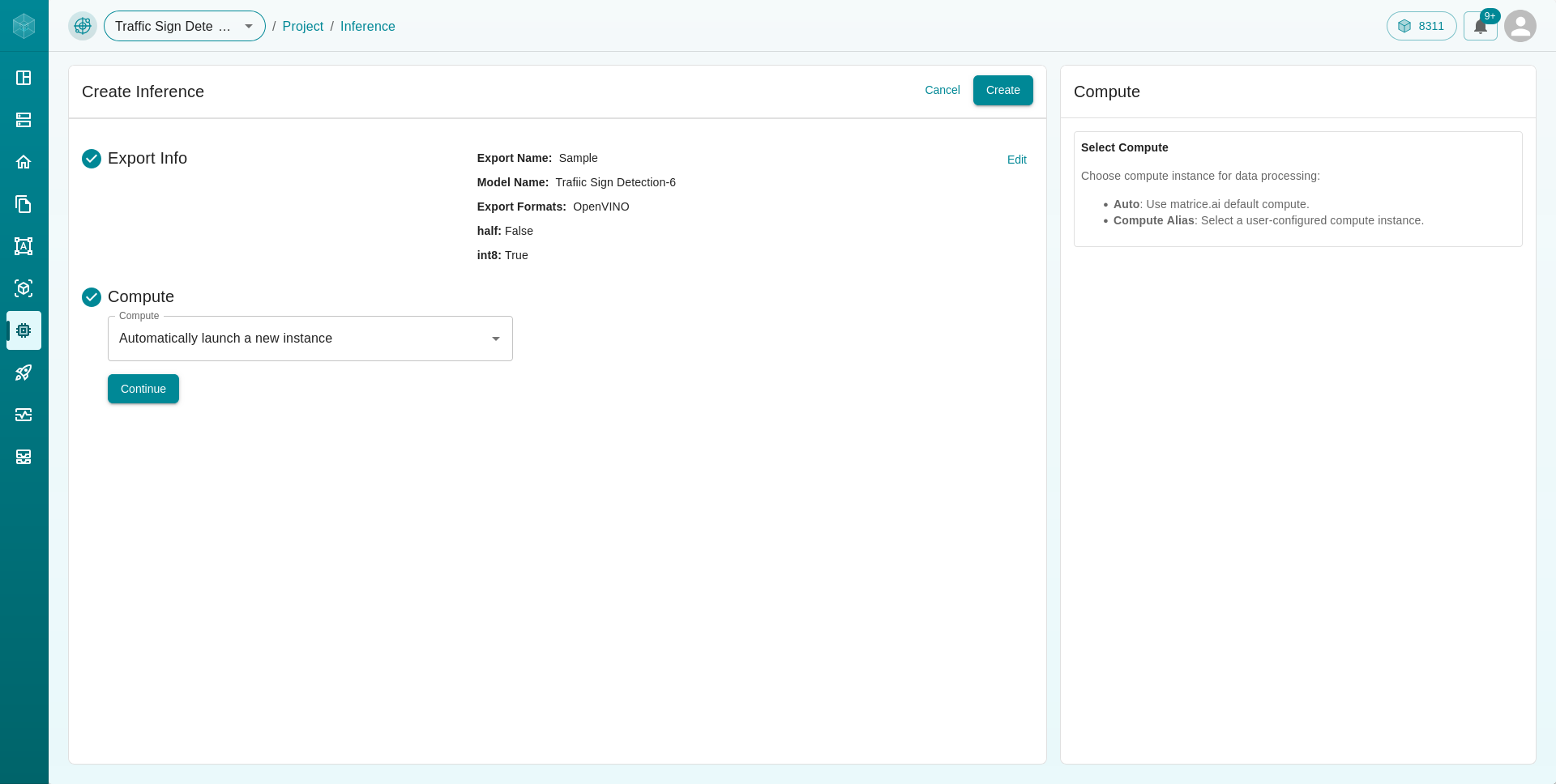
Click on Create button to add your models to export